* 큐(queue) 란 ?
- FIFO(First In Fisrt Out)
- 편하게 생각해보면 맛집에 줄 서있는 사람들을 떠올리면 될것이다.
(먼저 줄을 선 사람 순서대로 식당에 들어간다.)
- 그외에 번호표, 버퍼(buffer) 도 같은 개념이라고 보시면 되겠네요 !
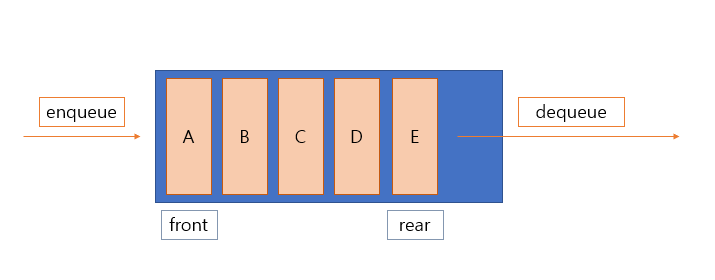
* 큐의 연산
- 삽입, 삭제, 비어있는지 확인, 맨 앞 (front) 확인,끝(rear) 확인 크기 등의 연산이 있다.
- 객체 : 선입선출(FIFO)의 접근 방법을 유지하는 요소들의 모임
연산 : enqueue(x)
dequeue()
front()
rear()
peek() -> front에 위치한 데이터 확인
empty()
- 시간 복잡도: (배열을 통한 구현으로 생각해보겠습니다.)
enqueue의 경우 배열 맨 끝에 추가하면 됩니다. O(1)
dequeue의 경우 배열의 앞에서 빼고 다른 요소들을 모두 하나씩 당기는 방식으로 구현할 경우 O(n)
(이경우 front는 무조건 index가 0일 것이므로 따로 index변수를 관리 할 필요가 없겠죠)
배열의 앞에서 빼고 front index를 따로 관리하여 +1만 해주는 경우 O(1) - 효율적
그 외 front(), rear(), peek() 등의 연산들은 index를 관리해줄 경우 모두 O(1) 타임 이겠죠?
* 큐 구현상의 문제점
만약 index를( 따로 front와 rear 를 가리키는) 관리해주는 방식으로 (효율적)
그럴 경우 배열의 크기는 정해져 있다는 것을 생각 해보면 계속 enqueue와 dequeue 작업을 수행하면
계속 뒤로 밀려지게 되다가 결국 배열의 크기를 넘어 가게 되면 오류가 발생하게 될 것 입니다.
이 때는 환형 배열을 이용 하면 이 방식의 문제를 해결할 수 있습니다.
만약 자료가 많아서 배열을 모두 채울경우 배열의 크기를 두배로 늘려서 다시 모든 요소들을 새로운
큰 크기의 배열로 옮겨주고 수행해야 하는 경우 enqueue 는 O(n) 타임이 걸릴 것입니다.
만약 연결리스트(링크드 리스트)로 구현할 경우 이러한 문제는 해결 할 수 있을것입니다.
하지만 링크드 리스트로 구현할 경우 코드상의 즉 런타임시간에 동적할당을 자주 해야 할것이고
이로인해 성능이 배열을 통해 구현한 순환큐 보다는 성능이 떨어질 수도 있습니다.
그러므로 만약 큐(자료)의 크기가 어느정도 예측이 가능할 경우 배열을 통한 순환큐가
더 적절한 상황이 나타날 수 있습니다.
* 큐 활용의 예
(큐의 특성을 생각해본다면 매우 많겠죠???)
- 프린트기
- 너비우선탐색(bfs)
- 은행업무
- 그외 등등
* 큐의 구현
< 배열 이용한 구현>


'학부생 공부 > 자료구조' 카테고리의 다른 글
| 트리 (Tree) (0) | 2020.10.14 |
|---|---|
| 그래프 (Graph) (0) | 2020.05.03 |
| 벡터(Vector) (0) | 2020.02.15 |
| 스택 (Stack) (0) | 2020.02.13 |
| Linked Lists (싱글 링크드리스트 구현 포함) (0) | 2019.12.31 |