1. 힙 메모리를 사용하는 이유?
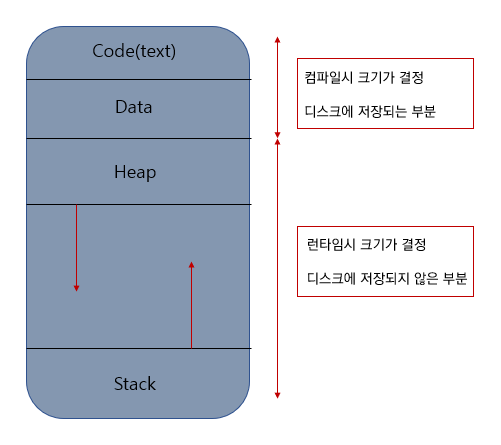
- 위의 그림에서 보듯이 heap의 공간과 stack 의 공간에 나누어져 있습니다.
- 그리고 stack메모리의 경우 사용되는 양은 런타임시 결정이 되지만 스택메모리의 최대 공간 (사용가능한) 은 컴파일 시
이미 지정이 됩니다.
- 왜 스택공간이 있는데 굳이 힙 메모리를 사용해야 하는가 ? 에 대한 궁금증이 떠오르게 됩니다.
- 제가 경험해보고 아는 선에서 몇가지만 이야기해보겠습니다.
-- (1) dynamic (동적할당)
알고리즘 문제를 풀 때 처럼 입력의 최대값이 정해져 있는경우 그 최대치로 메모리 공간을 할당해서 컴파일 시간
에 결정을 해서 스택메모리를 사용할 수도 있지만 (큰 사이즈의 경우 다음에 언급), 만약 사용자에 입력에 의해서
공간의 변동이 정해지는 경우 개발자 입장에서 미리 그 크기를 예측할 수 없으므로 런타임 시간에 변동에 맞게
메모리를 할당해야하는 경우 입니다.
-- (2) size 문제 (엄청 큰)
이전 게시글에서 언급했다싶이 stack memory의 경우 최대 사이즈가 미리 정해지는 만큼 엄청 큰 사이즈가 필요
할 경우 stack overflow가 발생할 수 있습니다. 이 때 스택에는 주소를 가리키는 포인터만 설정해주고, heap 메모
리 공간에 큰 사이즈를 선언해서 가리키게끔 할 수 있습니다.
-- (3) 스택메모리의 life cycle
스택 메모리의 경우 stack frame단위로 쌓이게 되는데 그 함수가 끝날경우 (life cycle)이 끝날 경우, 스택 메모리에
서 해제됩니다. 이 경우에도 어떤 데이터를 유지하고 싶을 때는 힙 메모리 공간을 사용합니다. (직접 해제 해주기
전 까지 힙 영역에 저장하고 있는 데이터는 사라지지 않으므로)
2. 힙 메모리 사용 in C++
- stack 메모리 대신 heap 메모리를 사용하는 경우는 필요한 용량이 매우 크다던지, dynamic(동적)으로 런타임 시간에
결정이 되는 변수를 사용한다던지 할 때인데요
- C++에서는 new를 통해서 힙에 공간을 할당 받고 스택 메모리에서의 포인터 변수가 이를 가리키도록 합니다.
- new를 통해서 할당을 받을경우 반드시 까먹지말고 delete을 해주어야만 메모리 leak을 막을 수 있습니다.
- new이외에도 unique_ptr 을 사용한다던지, 배열의 경우 vector를 사용하여 힙에 선언을 해준다면
- 메모리 해제 과정을 신경쓰지 않아도 되게끔 좀 더 안전하게 사용하실 수도 있습니다. 하지만 new를 사용하신다면
- 까먹지말고 반드시 delete으로 해제를 해주어야 한다는 점.!
3. stack 메모리 사용할 때와 heap 메모리 사용할 때의 차이점(장단점?)
- 우선 stack에 선언할 경우 속도가 더 빠릅니다.
- heap의 경우 원하는 만큼의 공간의 힙메모리상에서 찾고 할당하고 나중에는 이를 해제해야 하므로 상대적으로 시간이
- 많이 소요됩니다.
- 그럼에도 heap에는 큰 용량을 필요로 하는 변수라던지, 동적으로 결정이 되는 변수일 때 사용이 가능합니다.
- 그러므로 큰 사이즈가 아닌 경우 (100kb 미만? 정도?) 정도는 속도가 빠른 스택메모리를 사용하는 것이 좋습니다.
- 또 다른 차이점은 스택메모리의 경우 여러번수를 선언하고 주소를 찍어보시면 아시겠지만,
- 빽빽하게?? a가 4바이트를 차지하고, b가 4바이트를 차지한다면 메모리 주소도 4바이트(32bits) 차이가 납니다.
(물론 연속되게 위치하고 있을 경우를 가정)
- 중간에 빈 공간없이 빽빽하게 차지하지만, 힙의 경우 구멍이 송송뚤린 것 처럼 사이에 공간이 있습니다.
- 스택처럼 빡빡하게 메모리를 채우지는 않습니다.