0. 알아보기전에....
- 지금까지 insertion sort, quick sort, merge sort, heap sort 등....
에 대해서 알아보았습니다.
- 이러한 sorting 알고리즘들은 모두 두 수의 대소비교(key value에 대한) 를 하여 sort를 하는 class 의 알고리즘입니다.
- 두 수의 크기비교를 통해 정렬하는 알고리즘은 최적의(optimal) 알고리즘은 O(nlogn) 이라는 것도 확인 하였습니다.
1. radix sort (기수정렬)
- 먼저 언급하자면 , 이 sorting 알고리즘은 O(n) 이라는 수행시간을 가집니다.
- ?????? 최적은 O(nlogn) 이라는 것도 증명 하였는데 어떻게 O(n)에 수행하는 sorting 알고리즘이?!
- 그 이유는 크기비교가 아닌 다른 연산을 사용하기 때문에 class가 다른 algorithm이기 때문입니다.
- 즉 , 두 수간의 대소비교를 통한 어떠한 방법으로 정렬을 하는 것이 아니라는 뜻이죠
2. Strategy
- 그럼 어떻게 할 것인가.......?
- 선생님이 50명의 학생의 시험지를 점수별로 정렬을 시키고 싶은 상황이라고 해보자. (점수는: 0~99 <편의상>라 하자)
- 일단, 0.1.2.3.....9 까지가 적혀있는 박스 10개를 준비하자.
- 그리고 1의자리 수 를 기준으로 박스에 담자.
- 그 후 0번 박스부터 9번 박스까지 들어있는 종이를 다시 하나의 뭉텅이로 합친 후
- 이제 10의자리 수 를 기준으로 다시 0~9번 박스에 나누어 담자.
- 모든 점수는 최대 2자리 수 이므로 2번의 이 작업을 수행 하면 sorting이 완료 된 상태이다.
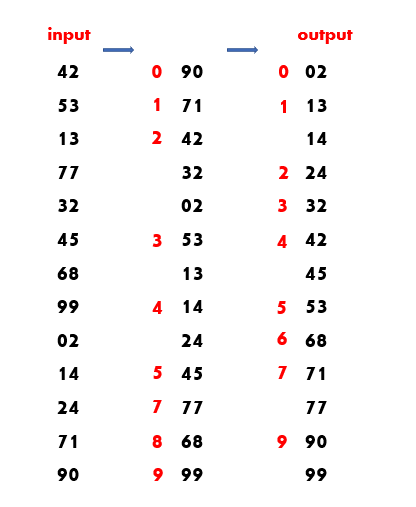
- 여기서 생각해보면 박스에 맞는 숫자를 담았을 뿐 두 수끼리의 비교하는 연산은 수행하지 않았다 !
- 이렇게 할 수 있었던 이유는 무엇 일까? 자료에 대한 정보가 더 있었기 때문에 가능했다.
(이 경우에는 점수 의 범위를 추가적으로 알고 있었다.)
- **stable**
: 이 알고리즘의 핵심 property 중 하나는 위에서(위의 상자부터) 순서대로(차례대로) 처리한다는 것
이럴경우 stable하다고 이야기 한다.
(즉, 같은 key값을 가진 input data가 여러개 있을 때 그 때 순서가 입력 순서와 같을 것을 보장한다는것)
--각 단계를 수행 할 때 ! (각 단계는 stable 해야한다.)
3. Algorithm
<list>이용



4. Analysis
- distribute --> Θ(n) (숫자보고 통에넣고.....n번 수행)
- combine -->Θ(n) (list 내용을 하나로)
- 이 작업을 몇번 수행 하느냐? 4자리수이면 4번....... 즉 자리수 (d) 만큼 (linear in n)
- O(n)
'알고리즘 > 정렬 (sorting)' 카테고리의 다른 글
| 4. Heap sort (힙 정렬)--(2) (0) | 2020.04.16 |
|---|---|
| 4. Heap sort (힙 정렬)--(1) (0) | 2020.04.16 |
| 3. Merge Sort (합병정렬) -구현 (0) | 2020.04.15 |
| 2. Quick sort(퀵 소트) -구현 (0) | 2020.04.14 |
| 1.Insertion sort (삽입정렬) - 구현 (0) | 2020.04.12 |