- 각각의 프로세스들은 독립적이므로, 하나의 프로세스가 죽더라도 다른 프로세스에는 영향을 끼치지 않는다.
- 하지만 멀티 스레드에 비해 더 많은 메모리공간과 컨텍스트 스위치로 인한 시간을 많이 차지한다.
- 여러개의 프로세스가 필요한 작업을 하나의 프로세스내의 여러개의 스레드로 나눠 수행하면 메모리 공간과 시스템 자 원소모, 실행시간을 줄일 수 있다.
2. 멀티스레드
- 멀티프로세스에 비해 적은 메모리공간 차지, 컨텍스트 스위치가 빠름
- 하나의 스레드에 문제가 발생하면, 다른 스레드들도 영향을 받을 수 있다.
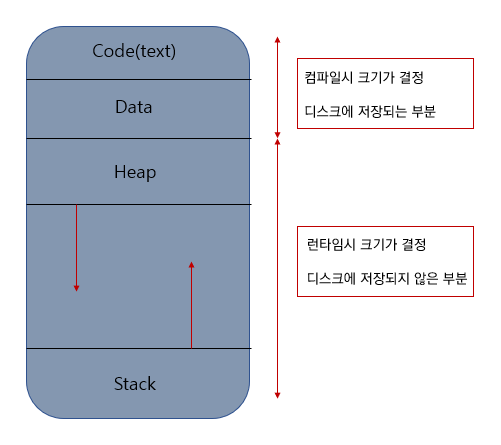
- 스레드간의 통신은 별도의 자원을 이용하지 않고, 전역변수나 힙 영역을 이용해서 데이터를 주고 받을 수 있다
( 스택은 각각 가지지만, 힙 공간은 공유함)
- 이 점은 문제가 되기도 한다.... 멀티 프로세스는 프로세스간 공유하는 자원이 없으므로 동일한 자원에 동시에 접근하지 않지만, 멀티 스레드는 서로 다른 스레드가 데이터와 힙 영역을 공유하기 때문에 잘못 수정하거나, 예상치 못한 값으로 수정되는 경우가 발생할 수 있어서 동기화 작업이 필요하다.
- 작업 순서와 공유자원 처리에 대해 신경써야 한다. 이 과정에서 병목현상으로 인한 성능 저하가 나타날 수 있다.