0. 프로그램이란?
- "실행할 수 있는 파일 ( 무언가 작업하기 위해 ) "
- ex) 윈도우의 exe 파일
1. 프로세스 란?
- " 실행되고 있는 컴퓨터 프로그램 (독립적) "
- 각 프로세스는 각각의 자원을 할당 받는다.
- 프로세스 간의 통신 위해서는 파이프, 소켓등을 사용해 통신한다. (비용이 상대적으로 많이 든다.)
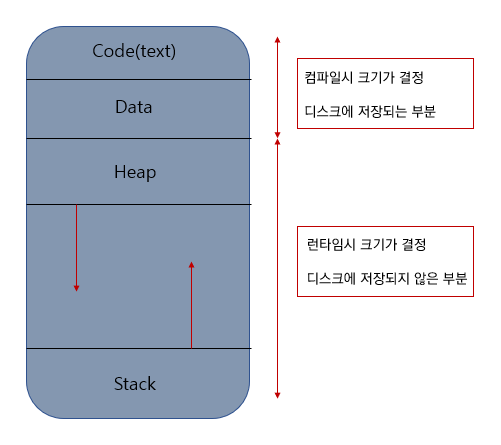
- Register, Counter, Stack, Heap, Code 으로 구성된다
- 시작, 종료, 컨텍스트 스위칭 시 비용(시간) 이 많이 소요된다.
- 프로세스 간의 전환에는 운영체제 호출을 필요로한다.

1-1. 프로세스 제어 블록(PCB) 란?
- 운영체제의 자료구조
- 프로세스에 정보를 저장하고 있다.
- 운영체제는 프로세스 생성과 함께 PCB를 생성한다.
- 프로세스 스위치가 발생하면 진행중이던 작업들은 PCB에 저장하고 CPU를 반환한다.
- 다시 CPU를 할당받으면 PCB에서 복원해와 종료시점부터 다시 작업을 수행한다.
- 프로세스 ID, 프로세스 상태, 프로그램 카운트(다음 실행 명령어의 주소), CPU레지스터 등이 저장된다.
2. 쓰레드 란?
- " 프로세스의 하나의 실행 단위 "
- 프로세스 안에서 각각의 작업을 처리한다.
- 프로세스 안에서 동시성(concurrency)을 가지고 진행한다.
- 한 프로세스 안의 여러개의 프로세스들은 Code, Data, Heap은 공유하고, 각각의 Stack을 가진다.
- 시작, 종료, 컨텍스트 스위칭 시 비용(시간) 이 적게 소요된다.
- 쓰레드 간의 전환에는 운영체제를 호출할 필요가 없다.
- 자원을 공유하는 만큼, 공유자원에 접근하고, 변경을 할 때 주의가 필요하다.
2-2. 멀티스레딩 이란?
- 하나의 프로세스를 다수의 실행 단위로 구분하여 자원을 공유하고 자원의 생성과 관리의 중복성을 최소화하여 성능을 향상시키는 기법
- 각각의 스레드는 각각의 스택과 PC레지스터 값을 가진다.
- 독립적 실행흐름을 위해서 스택은 필요하다. (각각 가지는 이유)
- 스레드는 하나의 실행 단위 이므로 PC레지스터를 통해 실행위치를 CPU할당에 따라 저장,복구하여 그 위치에서 다시 실행한다.
'학부생 공부 > 운영체제(os)' 카테고리의 다른 글
| 스케줄러(scheduler) 종류 (0) | 2021.09.20 |
|---|---|
| 멀티 프로세스 VS 멀티 스레드 (0) | 2021.09.19 |
| Context Switching ( 문맥 교환 ) (0) | 2021.05.27 |