0. 개요에 앞서....
-보통 string matching 문제를 해결하는 방식은 크게 두가지가 있는데
-1. pattern을 preprocessing하는 방법
-2. text를 preprocessing하는 방법
- 지금부터 살펴 볼 kmp나 booyer moore 알고리즘은 모두 패턴을 preprocessing하는 방식이다.
- text 자체가 잘 변하지 않거나 규모가 엄청 클 때는 2번의 방식을 사용하기도 한다.
1. 개요
- Knuth-Morris-Pratt's의 알고리즘 역시 브루트포스방식과 마찬가지로 왼쪽에서 오른쪽으로 텍스트와 패턴을 비교해 나가는 방식이다.
- 하지만 패턴을 옮길 때 브루트 포스보다는 조금 더 효율적인 방식을 사용한다.
2. 아이디어
- 브루트포스 방식에서 발생하는 중복되는 비교연산을 피하기 위해 kmp 에서는
- 패턴을 preprocessing하는 과정을 먼저 진행해서
- 패턴 비교가 실패한 지점에서 suffix중 가장 긴 prefix와 일치하는 지점을 찾아내서 이것은 비교하지 않고 건너뛴다.
- 말로 들으면 무슨말 인가 싶지만...

- 브루트 포스와 비교를 해보면 브루트포스방식에서는 단순히 패턴을 한칸 옮겼을 것이다.
그것과 비교해볼 때 kmp는 좀 더 효율적으로 패턴을 이동시켜 비교연산 횟수를 줄인다 !
- 그리고 prefix와 suffix가 일치하는 최대길이를 계산하여 이동시키므로 이동시킨위치보다 이전의 위치의 텍스트에서는
패턴이 발생할 수 가 없다!
3.preprocessing
- 이제 위의 아이디어를 사용하기 위해서는 패턴을 전처리를 해서 필요한 정보를 저장해두어야 할 필요가 있다.
- 보통 kmp failure function이라고 하는데, 패턴의 각 위치에서 prefix와 suffix가 일치하는 최대길이를 미리 계산해서 테 이블 형태로 저장해놓고 필요할 때 이 값들을 리턴해주는 함수이다.
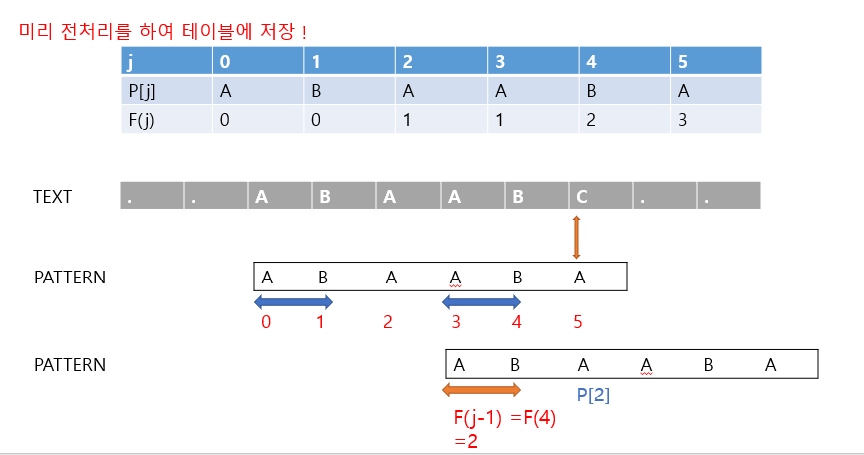
- 처음에는 눈과 손으로 직접 비교하면서 값들을 확인해보는 것을 추천드립니다.
- A , AB, ABA, ABAA, ABAAB, ABAABA 식으로 확인을 해보시면 됩니다.
4. 수도코드
- Failure Function

- KMP algorithm

5. 시간복잡도
- failure function은 최대 2m번의 비교를 통해서 구할 수 있으므로 O(n)
- 같은 방식을 사용하는 kmp는 failure function을 구하는 과정을 포함하여
O(n+m)의 시간복잡도를 가진다.
- 이는 브루트포스 방식의 O(m*n)에 비해서 매우 빠른 속도이다.
'알고리즘 > 문자열(string)' 카테고리의 다른 글
| 3.Boyer-Moore 알고리즘 (0) | 2020.10.08 |
|---|---|
| 1. Brute-force 방식 (0) | 2020.10.07 |